
Synthetic Training Data
Deep Vision Data® specializes in the creation of synthetic training data for supervised and unsupervised training of machine learning systems such as deep neural networks, and also the use of digital twins as virtual ML development environments. Lack of machine learning datasets is often cited as the major development obstacle for deep learning systems, and creating and labeling sufficient data from physical testing and other non-algorithmic methods such as photography can be extremely time consuming or impossible. The problem is further compounded when the product or process being studied is under development and no physical data exists, or if the items of interest are rare and underrepresented in the physical dataset. Synthetic training data also mitigates privacy concerns associated with medical data and other private information. Learn more about synthetic data at Wikipedia.
Our synthetic training data are created using a variety of proprietary methods, can be multi-class, and developed for both regression and classification problems. Data annotation is automatic, zero cost, and 100% accurate. Our machine learning datasets are provided using a database and labeling schema designed for your requirements. Contact us to discuss your particular machine learning data needs.


Data Generation Methods

In the News
Synthetic Training Data Used for Retail Merchandising Audit System
In this example created by Deep Vision Data, a deep learning model based on the ResNet101 architecture was trained to classify product SKU’s, stock outs and mis-merchandised products for a retail store merchandising audit system. The model was trained with 20,000 synthetic product images using a 50-50 split of structured and unstructured domain randomized subsets and an 80-20 training/validation data split. Model validation was also completely done with 100% synthetic training data. The test set was comprised of actual photos; a sampling of results images are shown to the right.
Domain randomization (DR) is a powerful tool available with synthetic data: it enables the creation of data variability that encompasses both expected and unexpected real-world input, forcing the model to focus on the data features most important to the problem understanding. DR is much more costly and difficult to implement with physical data. For example, the creation of a dataset of thousands of products where each product is shown in thousands of poses on dozens of backgrounds requires many millions of labeled images. That dataset is easily created synthetically, while virtually impossible to create using physical product photos. In addition, the distribution of rare (but possibly very important) events or conditions is easily controlled, unlike physical data where rare occurrences are by definition poorly represented.
Synthetic training data can be utilized for almost any machine learning application, either to augment a physical dataset or completely replace it. By effectively utilizing domain randomization the model interprets synthetic data as just part of the DR and it becomes indistinguishable from the physical information. Synthetic training data is inherently less costly, faster to create, perfectly annotated, and isn’t constrained by availability, time or even the physics of the natural world.

AiVision Virtual ML Development Platform
Proprietary development platform for training data, use activity and system optimization

Generate and Simulate Module Demonstrations

Product Images
Synthetic product images are 100% virtual and can include variability in pose, lighting, material finish and many other factors. Portions of the images can be occluded to simulate handling or other situations, and the renderings can be photorealistic, grey-scale or silhouette. Need a million images in a few days? No problem!

Hybrid Images
Need thousands of training images of your product presented in a specific physical environment, and you need them fast? Mobile devices running augmented reality (AR) apps can be utilized to quickly create hybrid images of virtual objects in physical environments. Useful for when the environment contains important class information or for domain randomization.

People and Environments
Synthetic environment images can be interior or exterior and include people, plants/trees and any inanimate object. Used to train systems to identify safety, compliance, stocking, manufacturing process deviations, traffic incidents, human behavior and many other functions. Scenes are database-driven to enable rapid configuration variation.

Real-Time XR Environments
Real-time simulators utilize game engines and custom software to replicate physical products, systems and processes. These Digital Twins are implemented in Extended Reality (XR) environments to create fully immersive training experiences. Multiple simultaneous instances of the real-time simulation environment can be utilized to rapidly speed up the training process.
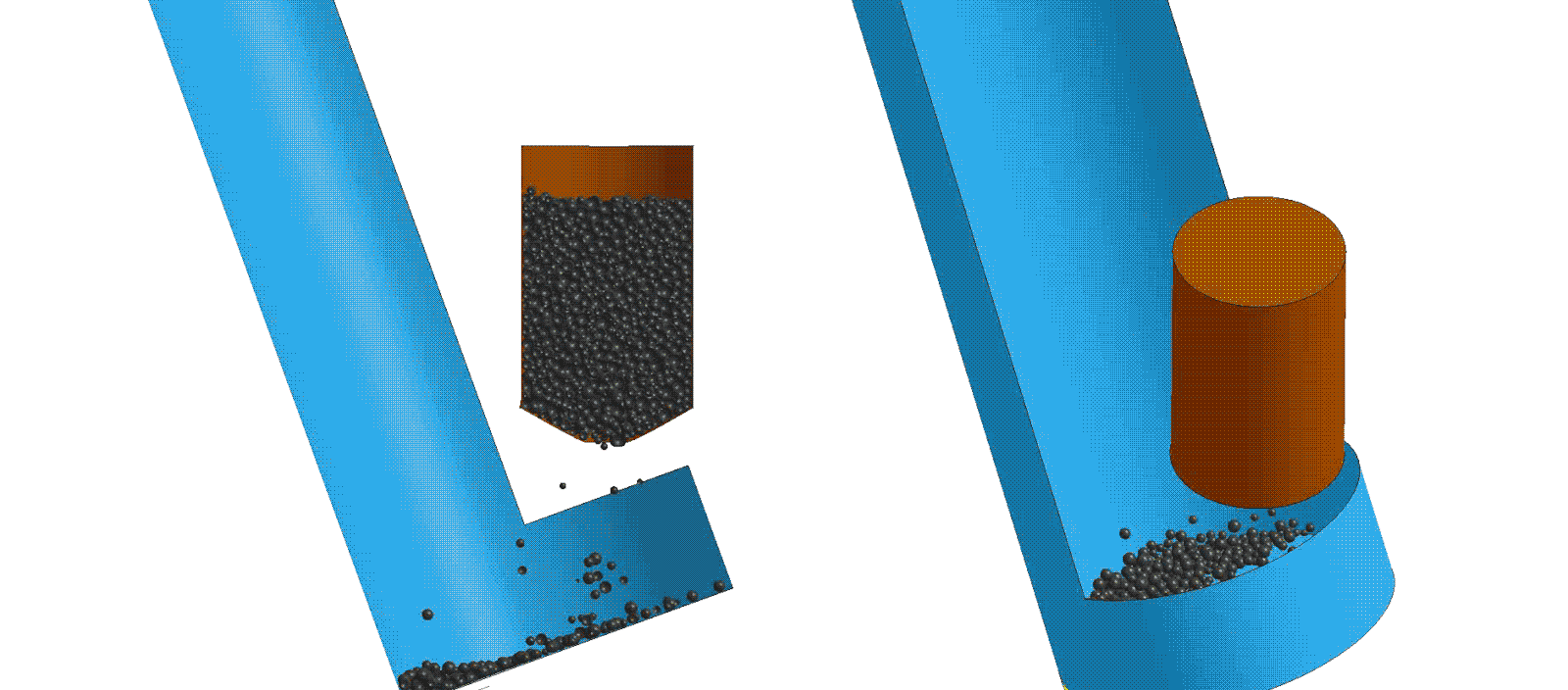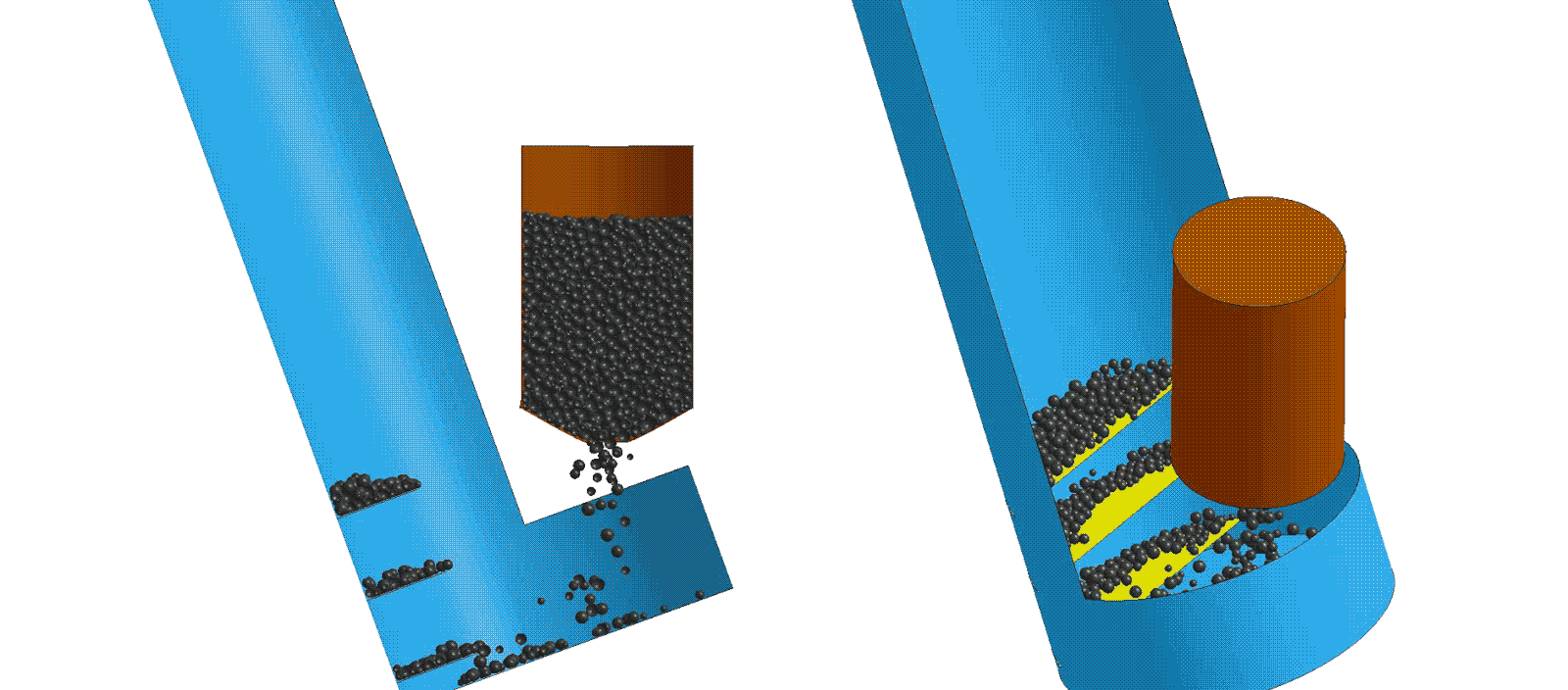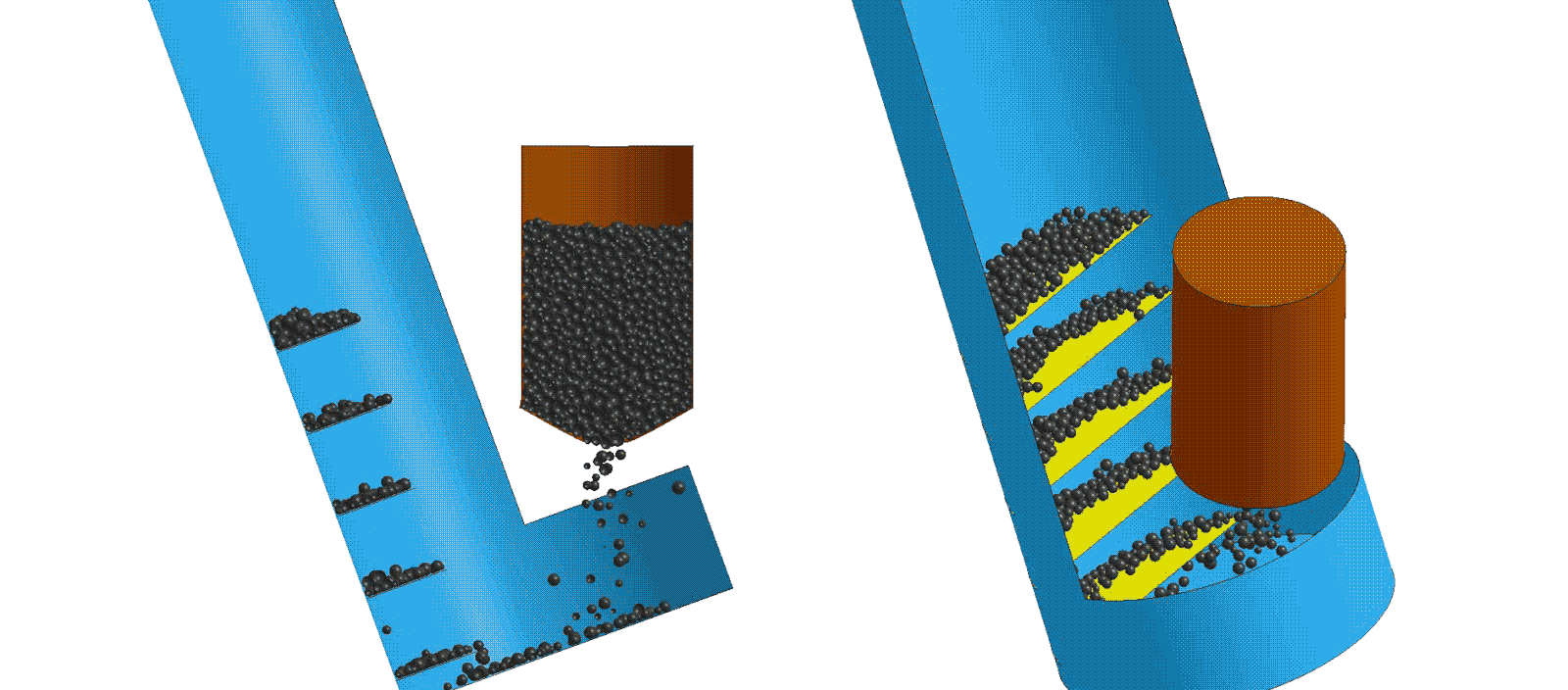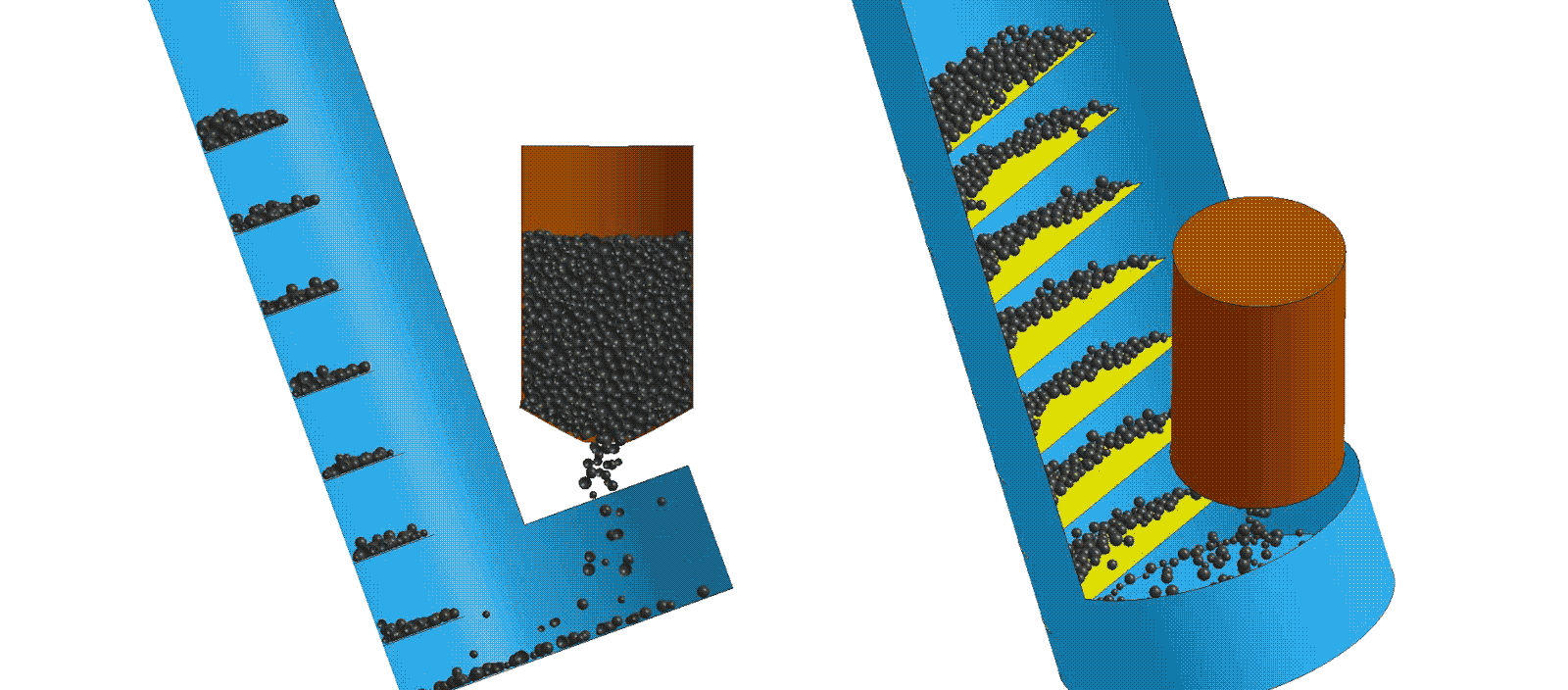
Modeling and Simulation
Modeling and simulation is used to explore product life cycle, performance, etc. due to variation in component dimensions, production quality, process parameters and other real-world variances. This data can be used to create intelligent CADTM systems that guide users to design products or systems which have optimized cost, performance or weight goals.

Design Variation
Computer-aided design (CAD) tools are used to algorithmically vary component dimensions or assembly parameters. The resulting data can be utilized to train intelligent production vision systems to identify manufacturing or quality issues that are too complex for traditional in-line processes. Coupled with industrial 3D scanning, machine learning creates the next evolution of part inspection.
Automatic Bounding Box, Semantic and Instance Segmentation
Our Vertical Markets
Deep Vision Data is the industry leader in synthetic training data for a range of markets
BIOHEALTH
AUTOMOTIVE
AEROSPACE / AVIATION
FINANCIAL
CONSUMER PACKAGED GOODS
FOOD PROCESSING / AGRIBUSINESS
ENERGY
POLYMERS / CHEMICALS
ADVANCED MANUFACTURING

Our Expertise
- Multi-disciplinary expertise in design, engineering, modeling and simulation software/app/simulator development, digital art and industrial 3D scanning.
- Proprietary software infrastructure for data creation, labeling and warehousing
- Ability to rapidly create product 3D models from physical samples or digital data
- Expertise with all major computer-aided design (CAD) and digital modeling software
- Expertise with all major modeling and simulation software systems
- Ability to create labeled training, validation and testing data sets for neural networks
Contact Us
All product names, logos, and brands are the property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Kinetic Vision is not affiliated with Post Consumer Brands, LLC , Honey Bunches of Oats, The Kellogg’s Company, Rice Krispies, Corn Flakes, Raisin Brain, General Mills, Cheerios, HoneyNut Cheerios, Ruffles, Kettle Brand, or Old Dutch Foods Inc.